
I recently switched the Rust version of Psychopath over from a binary BVH (BVH2) to a 4-branching BVH (BVH4). This is a fairly standard thing to do in a ray tracer to take advantage of SIMD operations on modern CPUs. With a BVH4 you can test against four bounding boxes at once with SIMD, which in theory can get you some pretty significant speedups.
However, my BVH4 implementation in Psychopath doesn't use SIMD, and is nevertheless faster than (or at least comparable to) my BVH2 implementation. This surprised me because I thought (?) the conventional wisdom was that a BVH4 is slower except when used to exploit SIMD.
So I'm writing this post to explain how I arrived here and why BVH4 might always be better.
A Back-of-the-Napkin Analysis
One of the things that makes BVHs (regardless of branch factor) a bit different than some other tree data structures is that in a BVH you have to test all of the children to figure out which ones to traverse into. You don't have to test them all at once—you can test against one child and immediately traverse into it if the ray hits it. But eventually you have to come back and test against the other sibling(s).
The reason for this is that BVH child nodes can overlap in space. Just because you found an intersection in one doesn't rule out a closer intersection in its siblings, so you still have to traverse into any that were hit to check for a closer intersection. This is true even if you test the nodes in front-to-back order.
(Note: in my discussion with François Beaune (of Appleseed fame), he noted that in theory you could store information about whether the children are overlapping or not. However, I don't think that changes this analysis, because you still on average have to test against multiple children, and such a trick would apply to all branch factors anyway. But I've been wrong before!)
So let's say we have a scene with sixteen triangles (or whatever geometry—I'll assume triangles). If we color in the nodes we test against in a minimal traversal that reaches a leaf, it looks like this for a BVH2 and a BVH4:
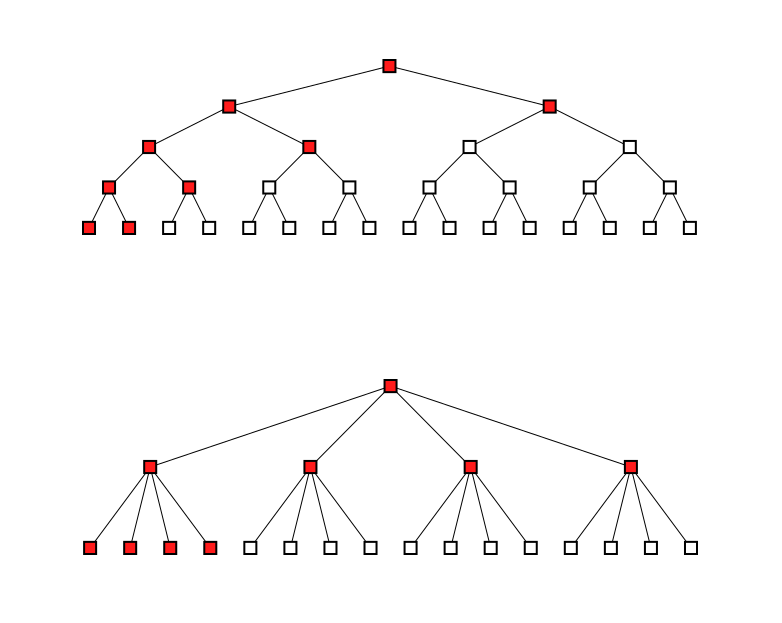
Interestingly, it turns out that it's nine nodes in both cases. And this equality holds true for any scene with any number of triangles.
For a BVH2 with N triangles, the number of nodes tested in this kind of minimal traversal can be computed with log2(N) * 2 + 1. And for a BVH4 with log4(N) * 4 + 1.
You can generalize this to any branch factor with logB(N) * B + 1, where B is the branch factor. If you take that equation and graph the number of node tests for various branch factors, you get a graph that looks like this:
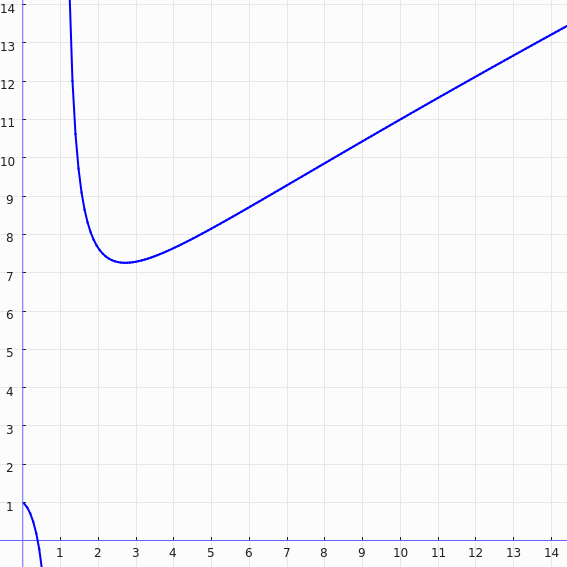
(X-axis is the branch factor B, and Y-axis is the number of node tests. Note that although this particular graph assumes a fixed N, the patterns hold for all values of N.)
There are a couple of things to note about this graph:
- It shows that, yes indeed, branch factors of 2 and 4 do the same number of node tests. Or put another way: the equations I gave above for a BVH2 and BVH4 are equivalent.
- When the branch factor exceeds 4, it starts doing worse and worse (more node tests). This is consistent with general wisdom that larger branch factors are progressively worse for efficiency. It just appears to not kick in until after a branch factor of 4.
(Also: 3. It seems to be the case that a branch factor of 3 is actually the most efficient. I haven't explored this at all, but it would be really cool if someone else would—I'd be very curious to see if it actually performs better. The tricky bit, I think, will be constructing a high quality tree with that branch factor.)
Implementation in Psychopath
There is still more analysis to cover, but this is the point in the analysis where my curiousity spurred me to try implementing it in Psychopath. So I'm going to take a brief detour to show what happened.
The implementation is pretty straight-forward. To build the BVH4, I first construct a BVH2 and then collapsing it down to a BVH4. I believe this is the standard way of constructing BVH4's. To traverse the BVH4 I use the technique described in Efficient Ray Tracing Kernels for Modern CPU Architectures by Fuetterling et al. to determine which order to traverse the nodes in (see section 2.2 in the paper). Importantly, that technique results in the exact same traversal order as my BVH2 implementation.
The primary implications of constructing and traversing the BVH4 this way are:
- The topology and bounding boxes of the BVH2 and BVH4 are equivalent: the BVH4 is just missing half of the inner nodes, skipping every-other level of the BVH2.
- As mentioned above, the traversal order of the BVH2 and BVH4 are identical.
- The leaf data (e.g. triangles) tested against due to the BVH2 and BVH4 are also identical.
In other words, the only difference between the BVH2 and the BVH4 is the branch factor itself.
Once I got everything working I did a bunch of test renders on various test scenes I have. Here are some of those renders (all rendered at 16 samples per pixel):

(Model by 'thecali', available on BlendSwap.)

(Model from SKYWATCH, a super cool short film.)


I rendered all of the test scenes with both the BVH2 and BVH4 to compare performance. Here are the render times (excluding BVH build time), calculated as best-out-of-five:
| Cars | Drone | City | Cornell(ish) | |
| BVH2 | 31.074s | 8.392s | 22.824s | 4.405s |
| BVH4 | 30.967s | 8.357s | 22.882s | 4.357s |
The only scene where the BVH2 beats the BVH4 is the city scene, and that's a bit suspect because it was an anomalously fast render among its five runs. But the main point is this: it appears that the non-SIMD BVH4 does indeed perform at least comparably to the BVH2.
A More Complete Analysis
The results from the render tests are largely consistent with the initial analysis. But there is nevertheless something important missing from that analysis: it assumes that for every parent, precisely one child will need to be traversed into. No more, and no less.
What if none of the children are hit? In that case the number of node tests looks like this:
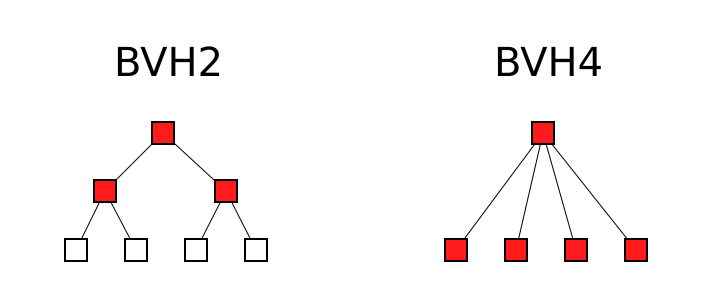
At first blush, this suggests that the BVH4 should be worse. Except... the render tests didn't bare that out. And that's because there is another case: all child nodes being hit. And that looks like this:
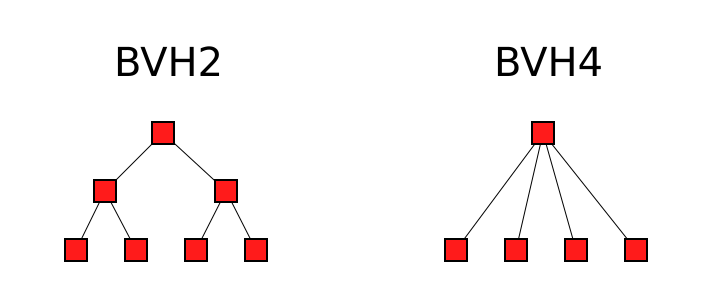
So the reality is that there are three cases for the BVH2:
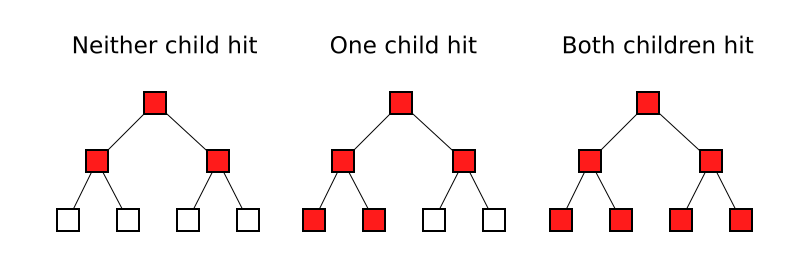
Basically, the BVH2 has both a better best case and a worse worst case. While the BVH4 always tests against all four children, the BVH2 can test against as few as two and as many as six children and grandchildren. Nevertheless, the average case is still the same for both the BVH2 and BVH4: four.
However! That's a very loose definition of "average". We're assuming that all cases are equally likely, but in reality that depends on the particular BVH and the particular rays being tested. This, of course, is the kind of thing that makes you curious: how many ray-node tests are actually being done in the test scenes?
So I instrumented the code to count all ray-node tests, and this is the result:
| Cars | Drone | City | Cornell(ish) | |
| BVH2 | 10619320877 | 2231421620 | 2788802110 | 386592706 |
| BVH4 | 10461971888 | 2153069143 | 2652842455 | 334467875 |
| % of BVH2 | 98.5% | 96.5% | 95.1% | 86.5% |
I don't claim that these are exhaustive test scenes by any means. For one thing, they're all shaded with gray lambert, and maybe the distribution of rays with other materials would change things. But nevertheless, this is at least interesting. In all of the scenes I tested, the BVH4 did fewer tests than the BVH2. Sometimes by a tiny margin, but it was always less.
Wrapping Up
So that's it. BVH4 appears to be at least comparable to BVH2 (if not a hair faster) even without SIMD. So for a more robust ray tracer implementation, BVH4 may be worth exploring. And not only for the potential (tiny) perf gains, but also because higher branch factors require fewer nodes and thus take up less memory.
Of course, there are some potentially confounding factors here:
- Psychopath does breadth-first ray tracing with thousands of rays at once, which means that the cost of any per-node computations other than ray tests get amortized over many rays. Specifically I'm referring to the traversal code lookup from Efficient Ray Tracing Kernels for Modern CPU Architectures, which might have more relative overhead in a more typical ray tracer. Moreover, if you don't use the traversal code approach, then you'll have to sort the four children based on ray hit distance, which is (super-linearly) more expensive than sorting two children.
- My test scenes are far from definitive! Testing with more production-like scenes, with complex shaders, depth complexity, etc. is still needed to make a strong case.
- I haven't done any analysis of the "overlap" flags idea that François suggested, much less any testing of it with actual scenes. I'm skeptical if this would have any branch-factor-specific impact, but I've been known to be very wrong about such things in the past! And at the very least, it's an interesting idea to explore.
I guess I'm not trying to make any especially strong claims with this (at least not in writing—buy me a beer some time). And since if you're writing a BVH4 you might as well use SIMD anyway, that makes most of this pretty moot. But for me this was nevertheless really fascinating to discover.
I hope this write-up made for an interesting read. And if anyone takes a crack at replicating these results, especially with more production-like scenes, I would be very interested to hear about it!