
(This post has been updated as of 2021-05-08 with important changes due to an issue identified by Matt Pharr. The majority of the post is essentially unchanged, but additional text discussing the issue and providing a new hash with the issue addressed have been added near the end of the post. If you just want the hash itself, skip down to the section "The final hash".)
At the end of my last post about Sobol sampling I said that although there was room for improvement, I was "quite satisfied" with the LK hash I had come up with for use with the techniques in Brent Burley's Owen scrambling paper. Well, apparently that satisfaction didn't last long, because I decided to have another go at it. And in the process I've not only come up with a much better hash, but I've also learned a bunch of things that I'd like to share.
Owen scrambling: what is it, really?
Before getting into the work I've done, let's revisit Owen scrambling.
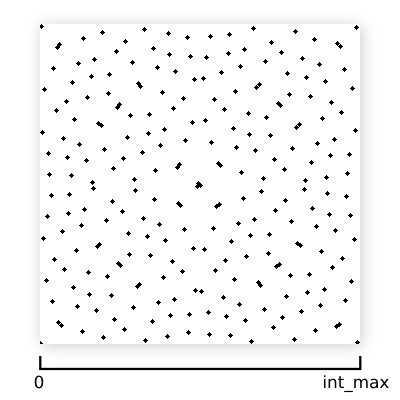
Let's say we have a bunch of Sobol points on the unit square:

To perform a single-axis Owen scramble we do the following recursive procedure: divide the current segment into two halves, randomly choose to swap those halves or not, and then recurse into each half and repeat.
Let's walk through a quick example: we start by deciding randomly whether to swap the left and right halves or not. In this case, let's say we do swap them:
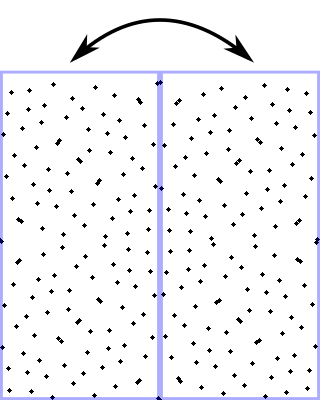
Then for each half we decide randomly whether to swap its sub-halves. Let's say we do for the left, but we don't for the right:
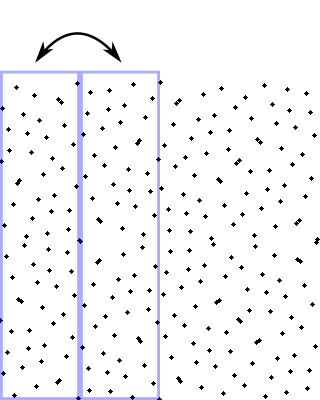
Then for each of those segments, we decide randomly whether to swap their left and right halves:
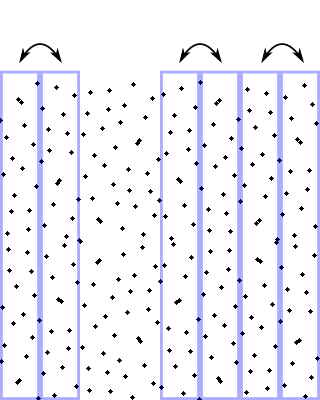
And so on, all the way to infinity (or to the precision of your numeric representation).
To scramble on the vertical axis as well, we just do the same random procedure vertically. And you can extend it to 3, 4, or a million dimensions by just repeating the process in all dimensions. Here are the same points, fully scrambled on both axes:

And that's Owen scrambling.1
Pretty simple, right? And remarkably, if performed on Sobol points, it not only preserves their great stratification properties, but actually improves their quality.
Thinking in bits.
The above explanation is, in my opinion, the most intuitive way to think about Owen scrambling. However, to build a hash that behaves the same way, we'll want to frame the process in terms of binary bits. So... here we go:
If we represent each point's coordinates with unsigned binary integers, with their range spanning the full extent of the square:
...then we can think of the scrambling process as making random bit-flipping decisions. For example, flipping the highest (most significant) bit of a coordinate for all points is identical to swapping the left and right halves of the square on that coordinate's axis.
One way we can visualize bit-flipping-based Owen scrambling is with what I'll be calling a "scramble tree". Let's take a four-bit binary number, 1101, as an example:
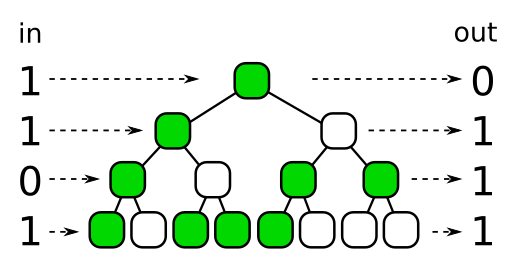
Each node in the scramble tree represents a bit flipping decision, with green = flip and white = don't flip.
The top node tells us whether to flip the highest bit or not. Then we move down the tree, going left if the highest bit was 0, and right if it was 1.2 The node we traverse into then tells us whether we flip the second-highest bit or not. Then we traverse left or right depending on whether that bit was 0 or 1. And so on.
If this scramble tree is generated randomly, and a different tree is used for each dimension, then it's equivalent to the more visual process I outlined earlier.
Implementing scramble trees in practice.
We could use scramble trees as an actual data structure to perform Owen scrambling. However, in practice the trees are too large to be practical: a 32-bit scramble tree is at minimum about 500MB. So instead we want something that behaves identically to a scramble tree, but without the storage requirement.
One way to accomplish that is to consider how we fill in the nodes with random values. We could use an RNG, of course, and just fill in one node after another. But there is another source of randomness we can use instead. Let's take a look at the tree again:
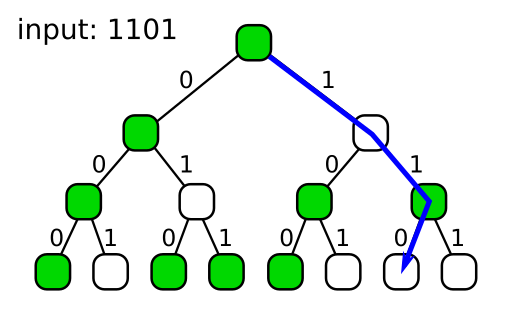
(I've notated the tree with 1's and 0's this time, indicating which input bit values correspond to which traversal paths.)
What we can see in this diagram is that each node has a unique "address", so to speak, which is simply the string of 1's and 0's that lead to it starting from the root. Utilizing those unique addresses, we can fill in the nodes with a good hash function: instead of using an RNG, we simply hash each node's address to get its random value.
What's great about that is it means we can drop the explicit tree altogether: since we can produce each node's value on demand with nothing more than its address, and since the address of the node we want is always just the string of bits higher than the bit we're making the flip decision for, we can just directly compute the node's value when needed without any tree traversal.
With this approach we still have a scramble tree, but it's implicit in the hash function we choose rather than being explicitly stored in memory.
Writing a function to do Owen scrambling this way is relatively straightforward, and in pseudo code might look something like this:
function owen_scramble(x):
for bit in bits of x:
if hash(bits higher than bit) is odd:
flip bit
return x
It simply loops through all the bits and flips each one based on a hash of all the bits higher than it.
This is awesome, but it's not quite enough for our needs. This function uses a single fixed hash function as its source of randomness, and is therefore equivalent to a single fixed scramble tree. However, we need a different scramble tree for each dimension, and if we want to decorrelate pixels with Owen scrambling then we even need different trees for each pixel. That's a lot of trees!
Fortunately, a small change lets us accomplish this quite easily. If we use a seedable hash function instead, then we can change the hash function (and thus the tree) by just passing a different seed value:3
function owen_scramble(x, seed):
for bit in bits of x:
if seedable_hash(bits higher than bit, seed) is odd:
flip bit
return x
And that's it! This function, if implemented properly and with a sufficiently good seedable hash function4, is a fully capable Owen scrambling function.
If you're curious, my actual implementation is here.
Owen hashing.
The line of reasoning I outlined above to arrive at this Owen scramble function focuses on scramble trees. And that's a really useful framing, because it's the framing that connects it to Owen scrambling. But if we shift our perspective a bit, there's an alternative framing that's also really useful: hashing. In other words, our Owen scrambling function doesn't just use a hash function, it actually is a hash function as well.
Specifically, in keeping with the insight from the Laine-Karras paper, it's a special kind of hash function that only allows bits to affect bits lower than themselves.
Since our goal is to create precisely such a function, that means we've already succeeded. Yay! And for many applications, using the above function is exactly what you want to do, because it is certainly high quality. However, for rendering it's a bit too slow. It executes a full hash for each bit, and that's quite a bit of CPU time.
Nevertheless, it serves as an excellent reference—a "ground truth" of sorts—that we can compare to while designing our LK-style hash.
One way we could make that comparison is to just eye-ball the resulting point sets, as I did in my previous post. We could also approach it with tools typical of point set analysis, such as comparing the frequency content of point sets via fast fourier transform.
But another way we can approach it is to take the "hash function" framing and evaluate our scrambling functions quantitatively as hash functions.
Evaluating hash functions.
One of the primary measures of hash function quality is avalanche. Avalanche is the extent to which each input bit affects each output bit. For a proper hash with good avalanche, all input bits should affect all output bits with close to equal probability.
Measuring avalanche is pretty straightforward: we take an input number and its resulting hash output, and then we flip each of the input number's bits one at a time to see which output bits flip with them. For a single input number, and a proper hash function, a graph of that looks like this:

The vertical axis is which input bit we flipped, and the horizontal axis is which output bits flipped with it. A white pixel means the output bit flipped, a black pixel means it didn't.
If we do this same process with a whole boatload of input numbers, and average the results together, we get an avalanche graph:

All pixels are a medium gray (modulo sampling noise). That means that, probabilistically, all input bits have a 50% chance of flipping any given output bit. This is exactly what you want from a proper hash.
We can also visualize the avalanche bias, which is simply the difference from that ideal 50% gray result. Black pixels then represent a 50% flipping probability, and anything lighter represents a deviation from that ideal:

As you would expect from a good hash function, it's just black. No significant bias.
Owen scrambling bias.
So what does our reference Owen scrambling implementation look like? Well, we have to be a little careful when computing its avalanche bias. Remember that our Owen hash is seedable, so it actually represents a set of hash functions. So what we actually want is to compute bias graphs for a whole boatload of different seeds, and average them together. That will give us the average bias.
If we do that, it looks like this:
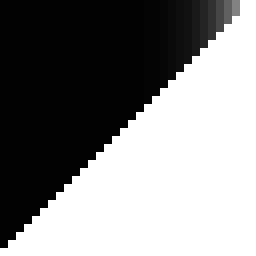
This is really interesting! If we were trying to build a proper hash function, this would be an awful result. There's tons of bias. Fortunately, we're not actually trying to build a hash function per-se, we're just exploiting hashing techniques to do Owen scrambling. And this is simply what proper Owen scrambling looks like when treated as a hash.
So this gives us a target to hit—a ground-truth result. There are a few interesting things to notice about it:
-
The entire lower-right half of the graph is pure white. This is what we want, and represents a critical property of Owen hashing: bits should only affect bits lower than themselves.
-
There is a single additional white pixel in the upper right. This is also expected: that pixel indicates the effect that the highest bit has on the second-highest bit. If you revisit the scramble tree, you can see that every possible tree configuration either causes the highest bit to always change the flip decision of the second-highest bit or never change it. You cannot create a tree with less than 100% bias between those two bits.
-
The upper-right corner has some gray that fades off as it moves left. This actually has the same cause as the extra white pixel: a limited set of possible tree configurations. This gray gradient is simply the average bias of that limited set. In fact, this precise gradient5 is an indication (though not proof) that the seeding is working properly, and producing all tree configurations with roughly equal probability.
How do the LK hashes compare?
So now that we have a ground-truth, we can compare our previous hashes. But we do have to address one thing first: as I mentioned in my previous posts, LK-style hashes actually do the opposite of an Owen scramble in the sense that instead of mixing from high bits to low bits, they mix from low to high.
So for convenience of comparison, here is the Owen scramble graph again, flipped to match LK-style hashes (this is what a "perfect" LK hash should look like):
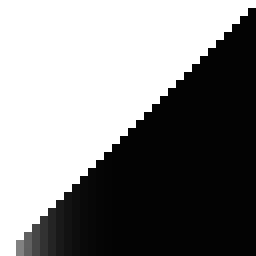
And here's the original Laine-Karras hash:

And here's the hash from the end of my previous post:
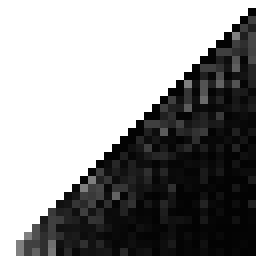
So... my "improved" hash from the previous post actually looks quite a bit worse than the original Laine-Karras hash, which is embarrassing. So... uh, yeah, don't use that one. (In my defense, the point sets it generates actually do have a more consistently "okay" FFT, but still.)
The original Laine-Karras hash has a curious line of gray along the diagonal, but otherwise looks pretty good over-all.
Both hashes suffer from having a very uneven/noisy gray gradient, and actually have less apparent bias in many pixels compared to the reference Owen scramble. Again, if we were developing a proper hash function, less bias would be good. But in our case that actually suggests that there are scramble trees they're not generating regardless of seeding. In other words, it means that the seeding process is biased.
Measuring seeding bias.
Seeing the issues with the gray gradient made me want a way to visualize that seeding bias more directly. The avalanche bias graph only gives an indirect indication of that issue.
What I came up with is based on this:
seed = random()
input1 = random()
input2 = random()
output1 = lk_hash(input1, seed)
output2 = lk_hash(input2, seed)
y = reverse_bits(input1 ^ input2)
x = reverse_bits(output1 ^ output2)
...and essentially making a 2d histogram of the resulting (x, y) points. The idea behind this is to reveal node relationships in the scramble tree that don't meaningfully change with the seed. Or, in other words, it provides some insight into what tree configurations the seeding process can produce.
In practice, a full histogram of this would be impractically large—it would be a 4294967296 x 4294967296 pixel image. So although the above code snippet is the idea, in practice I did some further manipulations to focus on the bits corresponding to the top of the scramble tree.
Both the base approach as well as the additional manipulations I did mean that this is far from perfect. It absolutely misses things. But it nevertheless provides more insight into our hash functions, which is good!
Anyway, here's what it looks like for the proper (bit-reversed) Owen scramble function:
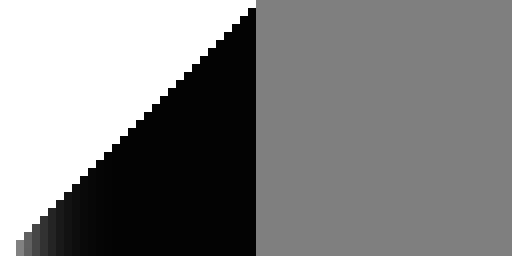
Here's the original LK hash:
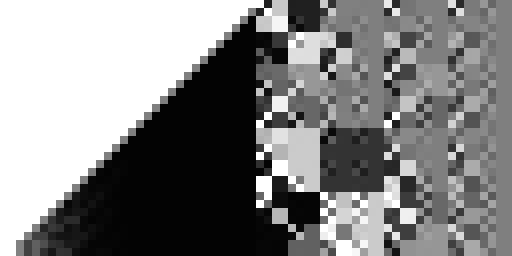
And here's my "improved" hash from the previous post:
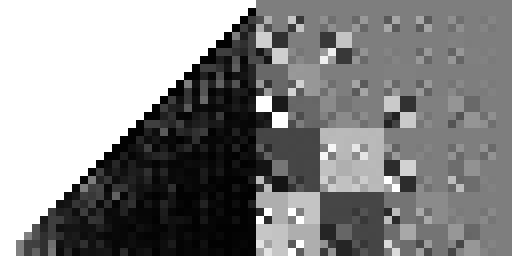
So it turns out both hashes are pretty bad. At least, in the sense that they are strongly biased away from particular tree configurations.6
Developing better LK-style hashes.
Since we now have some objective—even if incomplete—quality measures, some avenues for hash design have opened up. In particular, we can automate or semi-automate the search for better hashes by trying to maximize those quality measures.
I took inspiration from Hash Function Prospector, and wrote some code to randomly generate hashes from valid operations, and keep the hashes that most closely matched the measures of an ideal LK-style hash.
My hope was that this, on its own, would find some really great hashes. And although it certainly did find better hashes, in practice it required some intervention and guidance to find really good ones. In particular, I found that the following three-stage process tended to work well:
- Use a fully randomized search to look for sequences of operations that seem to work well.
- Take the best-performing of those op sequences, and do a search that only changes their constants.
- For the very best hashes that come out of that, compare them in the visual inspector that Brent Burley provided in the supplemental material of his Owen hashing paper. In particular, focusing on visually comparing their FFTs across a variety of seeds and sample counts.
The code I hacked together to do these evaluations and searches can be found here. It also includes a version of Brent Burley's visual inspector, with the hashes from this post included (including the full Owen scramble and the two hashes below).
The first results, and a problem.
The highest quality hash that initially came out of this process was the following:
(Note: please don't use this hash! It has an issue, discussed and fixed below.)
x *= 0x788aeeed
x ^= x * 0x41506a02
x += seed
x *= seed | 1
x ^= x * 0x7483dc64

The quantitative measures, while not perfect, appear very good. And visual inspection of both the resulting point sets and their FFTs was (as far as I could tell) essentially indistinguishable from a full Owen scramble. It's also no more expensive than the original Laine-Karras hash.
However, Matt Pharr identified a significant problem with this hash when testing it in PBRT. In short, if you run the following code which buckets outputs based on their lowest 8 bits:
any_constant = 123
buckets = [0, 0, 0, 0, ...]
loop for as long as you like:
seed = random()
buckets[owen_hash(any_constant, seed) & 0xff] += 1
...almost half of the buckets end up empty, and there is significant bias even in the buckets that aren't. Since you need to reverse the bits for Owen scrambling, those lowest bits become the highest bits, and it can end up being a real problem.7
After investigating a bit, I discovered that the root cause of the issue was this part of the hash:
x += seed
x *= seed | 1
The addition followed immediately by a multiplication with the same seed interfere with each other.
This is unfortunate because this sequence is otherwise remarkably good at producing Owen-scrambling-like behavior with a seed. There is no other sequence I could find that even comes close. Even just changing the order of the addition/multiply, or inserting other operations between them, significantly degrades the quality of the hash by the other measures in this post.
Fortunately, it turns out that the fix is easy: use two independent random seed values.
x += seed_1
x *= seed_2 | 1
This not only fixes the issue Matt found, but actually improves the other measures as well.
The downside is that it now requires 64 bits of random seed, rather than just 32 bits. This isn't a huge problem, but I wanted to keep it to 32 bits if I could. Some further investigation revealed this slightly hacky trick, which works really well in practice:
x += seed
x *= (seed >> 16) | 1
The idea here is to decorrelate the lower bits of the two operations. The bucketing issue is still present to some extent in the higher bits with this hack, but even with 2^24 buckets the distribution has very even statistics and only about 100 empty buckets. For 3d rendering, that's more than good enough, especially considering that 32-bit floats only have 24 bits of precision anyway. But if that nevertheless makes you uncomfortable, you can use a full 64 bits of seed instead.
In any case, if you simply drop either of these fixes into the hash above, it resolves the issue.
The final hash.
After figuring this out, I decided to do another round of random hash generation to see if I could get an even better LK-style hash. And it turns out the answer is yes!
So here is the final hash:
x ^= x * 0x3d20adea
x += seed
x *= (seed >> 16) | 1
x ^= x * 0x05526c56
x ^= x * 0x53a22864
This is much better than the previous results, and is remarkably close to the reference per-bit hash. Examining the FFT in Burley's visual inspector also appears essentially indistinguishable from a full Owen hash.
Please note that, just like the original LK hash, this hash needs random seeds to really work well. In Psychopath I pass incremental seeds through a fast 32-bit hash function before feeding them to this hash, and that works really well.
Wrapping up
One of the things that has made exploring this problem so interesting to me is that it's largely unexplored territory. It shares a lot in common with general hashing, but is nevertheless quite different in both purpose and quality evaluation.
I've taken a stab at developing such evaluation measures in this post, but as is clear from the problem that Matt Pharr found, they aren't complete. I feel reasonably confident that this final hash is good—certainly better than the original LK hash. But it's always possible there are still subtle issues. If anyone does discover issues with it, please contact me!
Footnotes
-
Actually, this is just Owen scrambling in base 2. Owen scrambling can be performed in arbitrary bases. For example, base 3 would divide each segment into thirds and randomly shuffle those thirds. For scrambling Sobol points, however, we want base-2 Owen scrambling, so that's what I'm focusing on here.
-
It doesn't really matter whether we traverse based on the input bits or the output bits—both conventions result in an Owen scramble, and both conventions are capable of representing all possible Owen scrambles. I use the input bits here because I think that's easier to follow. But it's worth noting that the visual Owen scramble process I outlined earlier in the post is better represented by the output bit convention.
-
If your seed is only 32 bits, of course, then it can't possibly provide enough variation to cover all possible 32-bit Owen scramble trees (each one being roughly 500MB large). But in practice this doesn't matter—we just need a good random sampling of Owen scramble trees. And a high-quality seedable hash function will accomplish that just fine.
-
There are actually some subtle ways you can screw up a real implementation of this, which I (repeatedly) learned the hard way. The final implementation can still be very simple, but I recommend looking at a real implementation to avoid those pitfalls. As for choosing a seedable hash function, I went with SipHash-1-3 in my implementation, passing the seed as SipHash's key. But there are almost certainly cheaper hash functions that will work just as well.
-
You can compute the expected gradient for this analytically using a little combinatorial math. Beyond the highest 16 bits (half the width of the graph), however, it becomes difficult to compute in practice due to the enormous numbers that the factorials produce. But I did compute it out to 16 bits, and it matches very closely.
-
It's not entirely clear that being biased in this sense is always a bad thing. For example, I wonder if being biased towards generating less biased trees might be a good thing for some applications. But being arbitrarily biased—rather than biased in a carefully engineered way—is probably a bad thing, which is what we're facing here.
-
Interestingly, if you do both scrambling and shuffling, like I am in Psychopath, the practical impacts of this don't manifest in any obvious way (which is why I didn't notice it). It turns out that shuffling is really good at hiding problems with scrambling. But if you do only scrambling—no shuffling—this problem shows up as subtle but noticeable artifacts at low sample counts.